XL2
Established Member
And it seems like it works!
I haven't tried on real hardware, but it should work too.
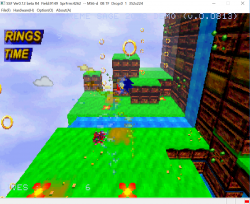
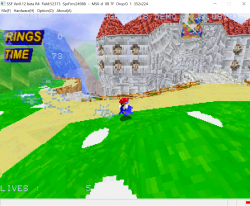
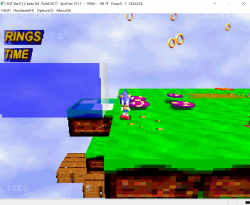
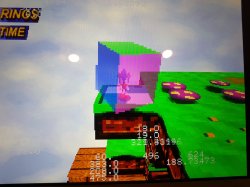
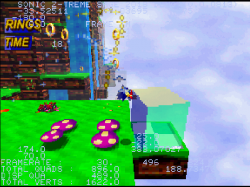
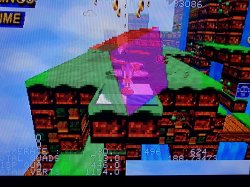
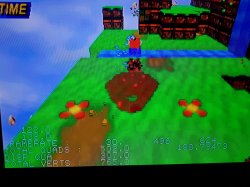
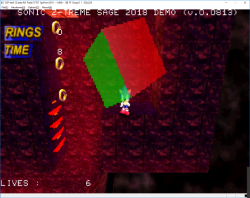
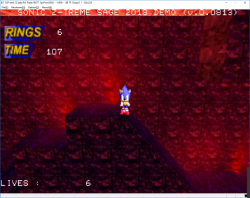
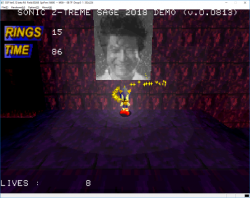
In these pictures, only the "sparkles" are using VDP2 transparency so it might be a bit hard to see.
It's also very low definition at just 160x112 so I guess it will look better with flat polygons and gouraud shading.
The only remaining issue is the scale as I just want to scale x by 0,455 and y 0.5 to have everything fit where it should go, but simply scaling my matrix will lead to issues (I just want screen space scaling).
Maybe I'll just manualy fix the draw commands or manualy generate draw commands, but it would be better to avoid always "patching" SGL and redo everything it does.
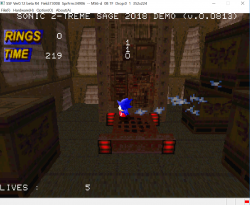
Edit : Added another picture with a basic box to better show how the transparency works on both VDP2 layers and VDP1. But the scale is still wrong, I will try to find a way to fix it this week.
I haven't tried on real hardware, but it should work too.
In these pictures, only the "sparkles" are using VDP2 transparency so it might be a bit hard to see.
It's also very low definition at just 160x112 so I guess it will look better with flat polygons and gouraud shading.
The only remaining issue is the scale as I just want to scale x by 0,455 and y 0.5 to have everything fit where it should go, but simply scaling my matrix will lead to issues (I just want screen space scaling).
Maybe I'll just manualy fix the draw commands or manualy generate draw commands, but it would be better to avoid always "patching" SGL and redo everything it does.
Edit : Added another picture with a basic box to better show how the transparency works on both VDP2 layers and VDP1. But the scale is still wrong, I will try to find a way to fix it this week.
Attachments
Last edited:
")

